
Exclusively for Members
Repertoire—The Walkthrough App
Confidently get into classrooms every day
Have feedback conversations that change teacher practice
Discover your best opportunities for school improvement
Compatible with all devices & evaluation frameworks

21-Day Program
Instructional Leadership Challenge
Build a sustainable classroom visit habit in just 21 days. Daily prompts, peer accountability, and a proven framework keep you on track.
Daily visit prompts and reflection questions
Cohort-based accountability with fellow leaders
Instant access—start your first visit today
Applying For Admin Jobs?
Rapid Interview Prep Toolkit
Walk into your next principal or AP interview ready to stand out. Practice questions, answer frameworks, and proven strategies from leaders who landed the job.
52 real interview questions with model answers
Step-by-step answer framework for any question
Download instantly and prep on your own schedule


Downloadable Resources
Classroom Walkthrough Toolbox
Ready-to-use templates, checklists, and conversation guides for every step of the classroom walkthrough process.
Walkthrough observation forms and look-fors
Feedback conversation starters and scripts
Print-ready PDFs you can use tomorrow
10 Matched Sets
Ed Leadership Job Application Template Bundle
Professional templates for cover letters, resumes, and leadership portfolios designed specifically for school administrators.
Cover letter and resume templates for admin roles
Entry plan and leadership philosophy frameworks
10 matching sets of editable Microsoft Word templates

Build Capacity For Instructional Leadership
Four integrated tools designed for the way principals actually work — fast, mobile, and built around classroom visits.
10:16 Teacher circulating, checking work samples
10:18 Clear learning objective posted on board
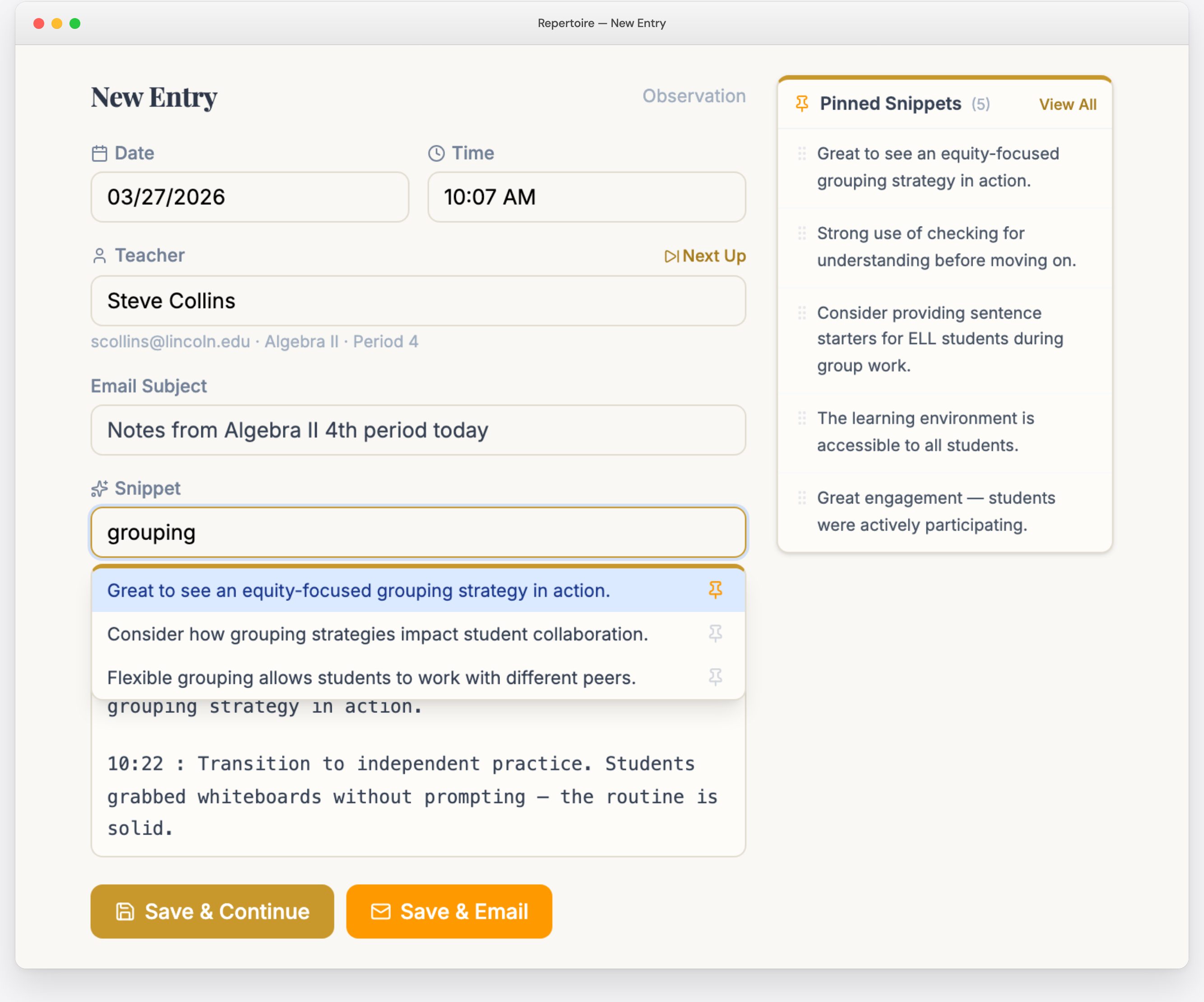
Repertoire
Get into every classroom. Give feedback in 60 seconds.
- Next Up button tells you who to visit next
- Reusable snippets aligned to your evaluation framework
- Save and email feedback from your own address
Voice memo — 0:47
Captures
Voice memos and photos, turned into action.
- Record audio or photograph documents on the go
- AI transcribes and extracts key details automatically
- Convert to entries, tasks, or contacts in one tap
Today
Traction
A task manager built for principals.
- Today view shows only what matters right now
- Natural language input — just type what you need to do
- Weekly Review keeps your priorities on track
Contacts
Rivera, Carmen — AP
Last contact: 2 days ago
Williams, Tom — Dept Head
Overdue for check-in
Network
Never forget who needs what.
- Touch logs track every interaction with staff and contacts
- Check-in reminders surface people you haven't connected with
- Rich notes and tags for every relationship
Ascend Career Toolkit
Advance your career with confidence
Purpose-built tools for the next step in your leadership journey.
Tracker
Track every application from posting to offer
Portfolio
Build your leadership experience library
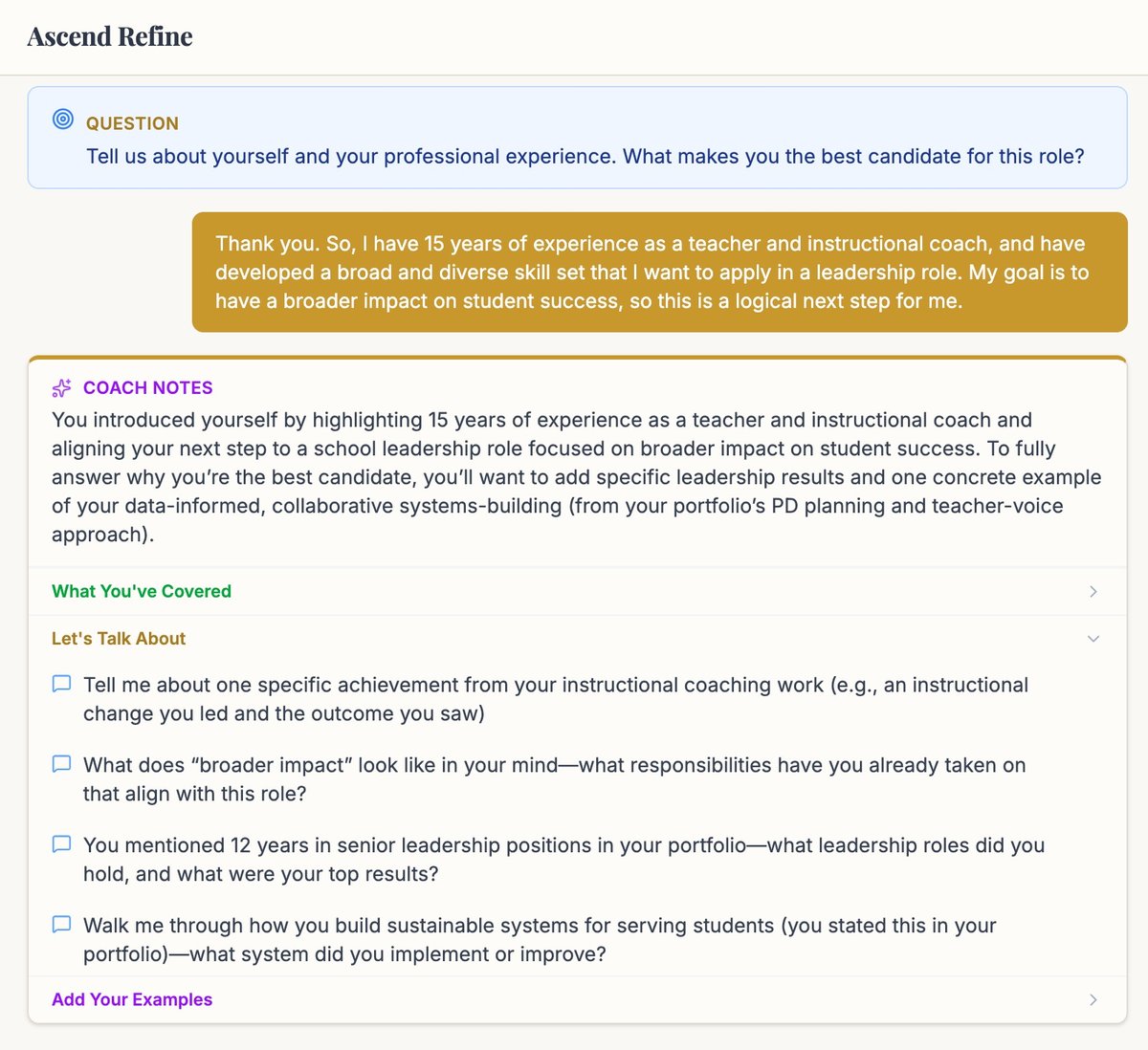
Refine
AI coaching for stronger application answers
Interview Prep
Practice with real principal interview questions
Start fast. Stay accountable.
Two features built around the hardest part of instructional leadership: actually getting into classrooms, consistently, every week.
Free — No Membership Required
Portrait
5 photos — 15 minutes — ready to go
A guided challenge that gets new members into classrooms immediately—no videos to watch, no modules to complete. Take five photos and you’ll have visited a classroom, loaded your roster, and configured your observation tools.
Take the Portrait Challenge (free) →
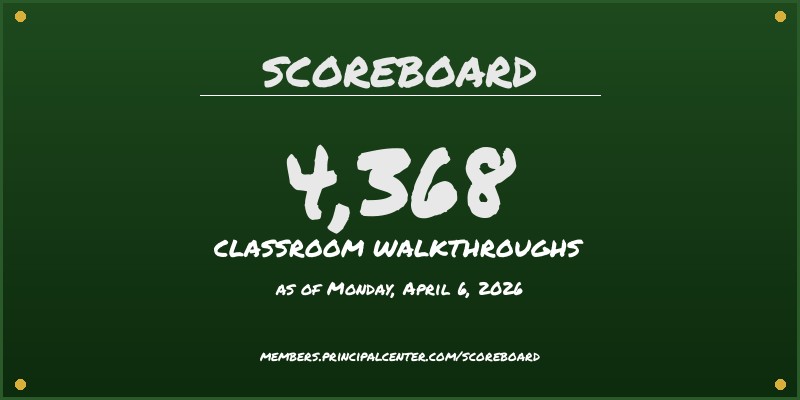
A public, opt-in leaderboard that celebrates classroom visit progress. Your number only goes up—no shame, no “zero weeks.” Members who opt in are visible to colleagues. It’s accountability that feels like community.
See the live Scoreboard →
Learn from the best in instructional leadership
Weekly content to sharpen your practice and stay current on what works.
Instructional Leadership Show
Weekly video episodes with practical strategies for getting into classrooms and leading instruction.
Watch episodes →Marshall Memo
Kim Marshall's weekly digest of the most important K-12 research and news, curated for busy leaders.
Included with membership →Courses & Certifications
Classroom Walkthrough Certification, Teacher Evaluation Certification, Ascend Masterclass, and more.
View courses →Books by Justin Baeder, PhD
Three books for building capacity for instructional leadership at every level.

Now We're Talking!
The definitive guide to classroom walkthroughs. Build the daily habit of getting into classrooms, having substantive conversations with teachers, and leading instructional improvement with confidence.
Learn more →
Mapping Professional Practice
A practical guide for school and district leaders who want to create or refine an instructional framework that actually drives teacher development — not just compliance.
Learn more →
Cultivate & Activate
How to develop teacher leaders who can drive instructional improvement alongside administrators — building shared ownership of teaching quality across the school.
Learn more →Principal Center Radio
Interviews with education's best authors and thinkers. Free everywhere you listen.
April 11, 2026
Dr. Frank Rodriguez and Dr. Gene Tavernetti—Digital Captives: Helping Schools Strike A Balance Between Humans And Hardware
Listen →
April 6, 2026
Barbara Blackburn—Productive Struggle in the Classroom
Listen →
March 30, 2026
Priten Soundar Shah—Ethical Ed Tech: How Educators Can Lead on AI and Digital Safety in K-12 Schools
Listen →
March 30, 2026
Priten Soundar Shah—Ethical Ed Tech: How Educators Can Lead on AI and Digital Safety in K-12 Schools
Listen →
Videos
Short videos on discipline, grading, instructional leadership, and more.
Away for the Day Is the Best Phone Policy for Schools
Watch →
Vygotsky Was Not a Constructivist in the Way We've Been Led to Believe
Watch →
Abby Zwerner's Lawsuit Can Proceed — Judge Rules It's NOT a Workers' Comp Issue
Watch →
When Did 'Trauma-Informed' Become a Euphemism for Low Expectations?
Watch →
How to Prepare for a Virtual Screening Interview
Watch →
Go Slow to Go Fast: Stop Constantly Starting New Initiatives
Watch →
Articles
In-depth guides for instructional leaders.
Principal Center Radio
Free interviews with education’s best authors and thinkers. New episodes weekly.
April 11, 2026
Dr. Frank Rodriguez and Dr. Gene Tavernetti—Digital Captives: Helping Schools Strike A Balance Between Humans And Hardware
Listen →
April 6, 2026
Barbara Blackburn—Productive Struggle in the Classroom
Listen →
March 30, 2026
Priten Soundar Shah—Ethical Ed Tech: How Educators Can Lead on AI and Digital Safety in K-12 Schools
Listen →
March 21, 2026
Darin Thompson–The Four Cornerstones of Effective Schools: How to Build Lasting Success
Listen →
The Eduleadership Show
Video and audio episodes on instructional leadership practice.
March 1, 2026
Kim Marshall on Teacher Evaluation, Feedback Conversations, and Artificial Intelligence
Listen →
January 30, 2026
Principal Justin Johnson on Tier 3 Systems for Learning
Listen →
December 5, 2025
Accommodations at Elite Colleges; Bloom’s 2-Sigma Problem; Overhyped AI EdTech
Listen →
November 14, 2025
Why It's Hard To Evaluate Microschools; Remedial Math at UCSD; Sweden Rolls Back Tech in Childhood
Listen →
The Teaching Show
Video episodes on what great teaching looks like in practice.
April 10, 2026
Classroom Management Today with Gabriel Vigil
Listen →
January 23, 2026
Brain Dump + Turn & Talk + Gist Statements for Reading Comprehension with Faith Howard
Listen →
January 16, 2026
Mini Whiteboards for Retrieval Practice with Dr. Janell Blunt
Listen →
December 23, 2025
Lightweight Approaches To Interdisciplinary Teaching with Lauren Brown
Listen →
Trusted Worldwide
More than 15,000 leaders in 50 countries
Principals, assistant principals, instructional coaches, and district leaders use The Principal Center to build capacity for instructional leadership.
Ready to lead with confidence?
Join thousands of instructional leaders who use The Principal Center to get into classrooms, give better feedback, and drive real improvement.